Publications
* First authors, † Corresponding authors
2026
- MICCAI (Early Accept)
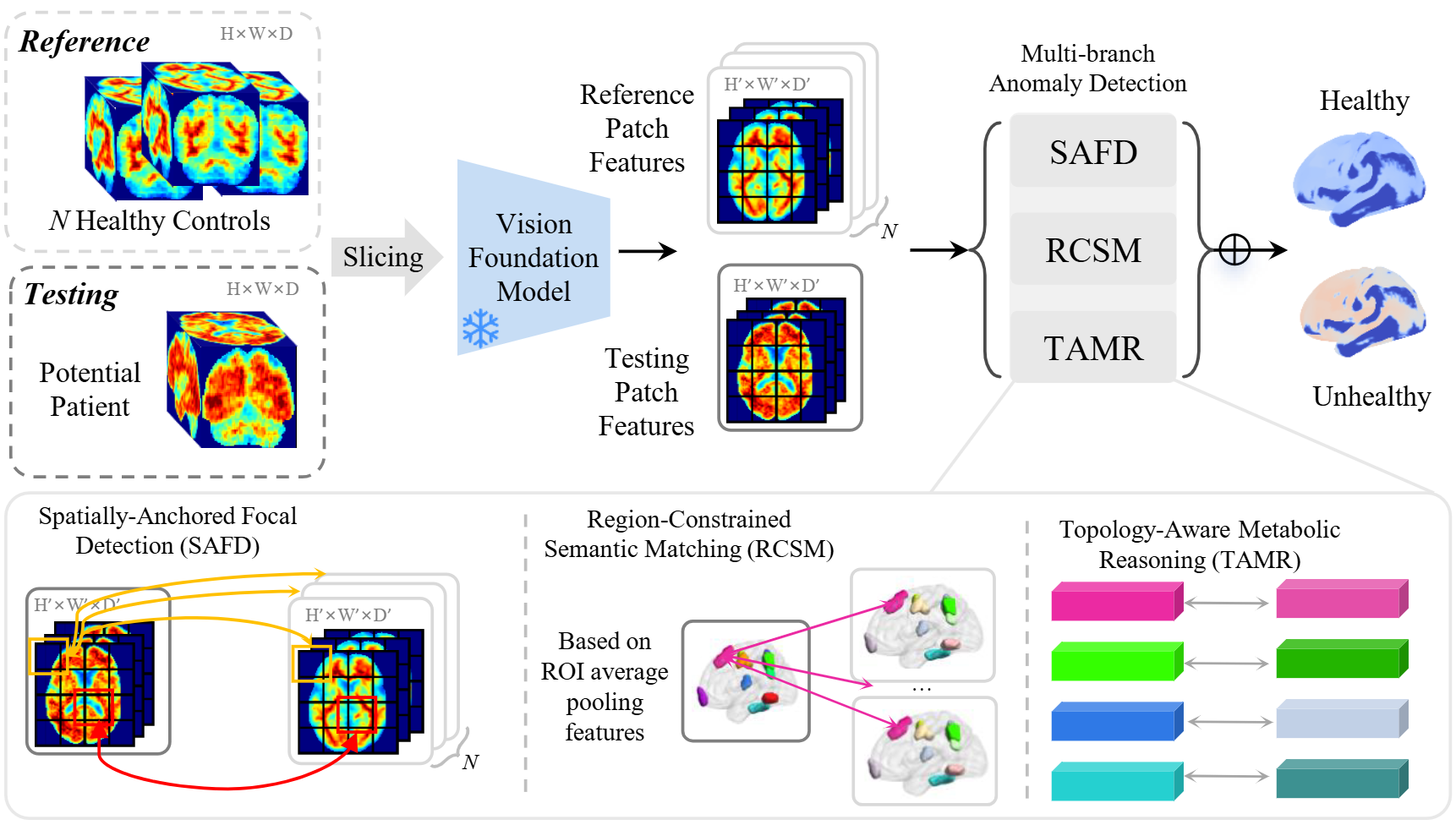 TracerAD: Training-Free Few-Shot 3D Anomaly Detection for Novel PET TracersHaolin Huang*, Junlei Wu*, Jiaying Lu, Zhenrong Shen, Xinyu Wang, Chuantao Zuo, and Qian Wang†In Medical Image Computing and Computer Assisted Intervention , 2026
TracerAD: Training-Free Few-Shot 3D Anomaly Detection for Novel PET TracersHaolin Huang*, Junlei Wu*, Jiaying Lu, Zhenrong Shen, Xinyu Wang, Chuantao Zuo, and Qian Wang†In Medical Image Computing and Computer Assisted Intervention , 2026The deployment of PET tracers faces a cold-start dilemma in two common scenarios: when a novel tracer enters early clinical use with scarce healthy controls (HCs) and no diagnostic labels, and when an established tracer is introduced at a new site or resource-limited region where normative references have yet to be accumulated. Existing anomaly detection methods require large training cohorts or operate only on two-dimensional slices, failing to address the joint demands of extreme data scarcity and volumetric reasoning. We propose TracerAD, a training-free few-shot framework for three-dimensional brain PET anomaly detection that requires only a handful of HC scans and no model training. TracerAD extracts frozen vision foundation model features from registered brain volumes and detects pathological deviations at three spatial scales: coordinate-level focal detection (SAFD), atlas-constrained regional matching (RCSM), and graph-based inter-regional metabolic reasoning (TAMR), producing a clinically interpretable 3D anomaly heatmap. Evaluated on an amyloid PET dataset from the Alzheimer’s Disease Neuroimaging Initiative (ADNI) under 1- to 10-shot settings, TracerAD achieves competitive detection performance without any training or fine-tuning, offering a practical tool for accelerating PET tracer deployment across diverse clinical settings.
- MICCAI
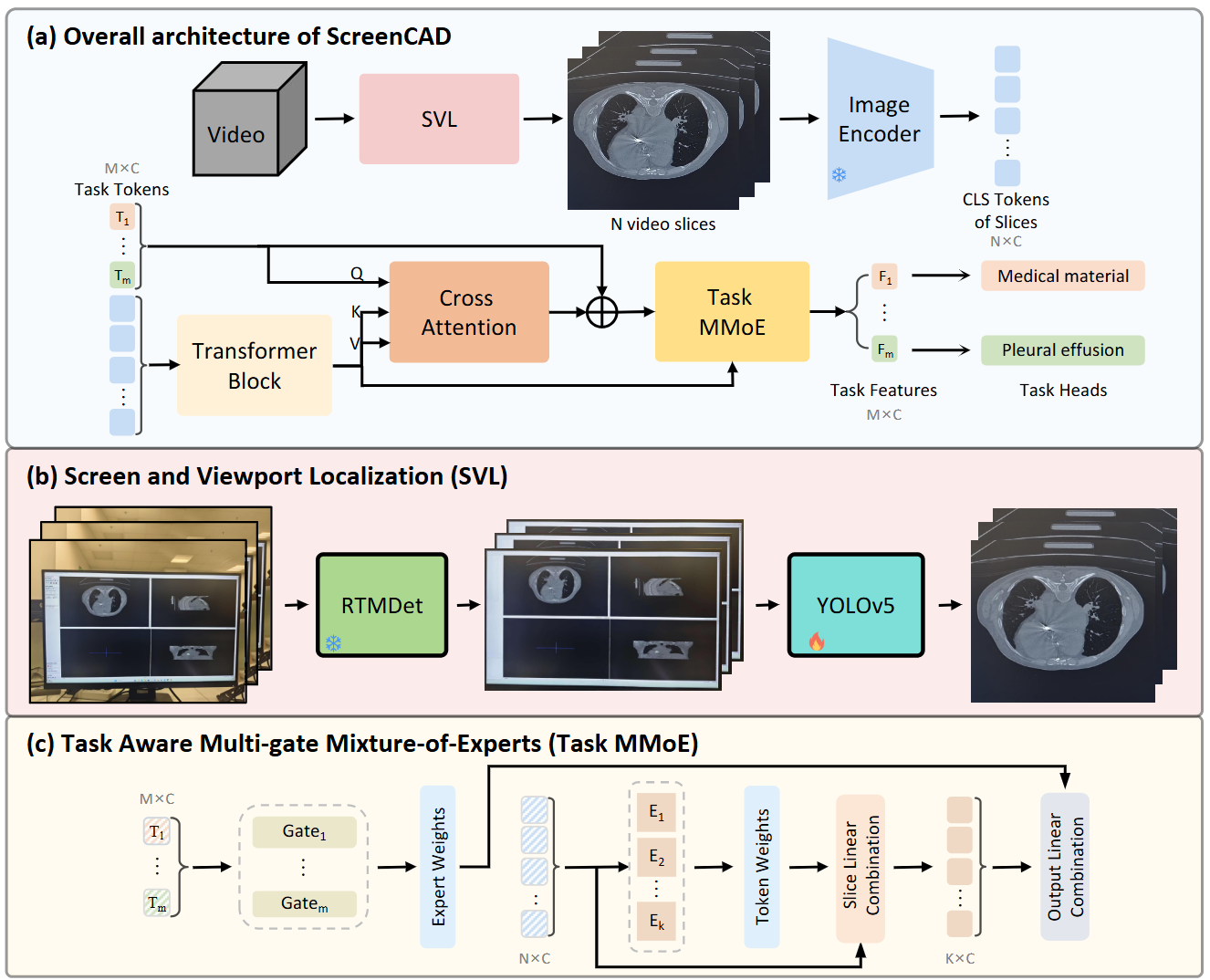 Diagnosing 3D Volumes from Camera Video: A Semantic-Robust Framework Without Direct DICOM AccessJunlei Wu*, Haolin Huang*, Jiaming Li, and Qian Wang†In Medical Image Computing and Computer Assisted Intervention , 2026
Diagnosing 3D Volumes from Camera Video: A Semantic-Robust Framework Without Direct DICOM AccessJunlei Wu*, Haolin Huang*, Jiaming Li, and Qian Wang†In Medical Image Computing and Computer Assisted Intervention , 2026Medical imaging traditionally assumes that high-fidelity, lossless data are required for reliable computer-aided diagnosis (CAD), an assumption inherited by AI models trained on pristine DICOM volumes. While 2D radiographs have shown tolerance to smartphone recapture, it remains unknown whether 3D volumetric diagnosis can survive the severe degradation introduced when a camera records slice scrolling as a video stream. This question is increasingly relevant as DICOM-level access and PACS integration impose substantial infrastructural barriers, particularly in resource-limited settings. We introduce ScreenCAD, the first framework to test whether a 3D medical volume, transformed into a camera-captured video, still preserves sufficient semantic information for AI diagnosis. ScreenCAD combines cascaded ROI extraction, a frozen medical foundation model with strong semantic invariance, and a Task-Token Mixture-of-Experts aggregator to operate directly on low-fidelity, variable-length video streams. On CT-RATE with real-world screen recordings, ScreenCAD achieves near-parity with its clean-DICOM performance, while conventional 3D baselines degrade sharply. These results provide the first evidence that volumetric diagnosis can remain reliable under substantial information loss, highlighting camera-based acquisition as a practical and scalable interface for future medical AI systems.
- MICCAI
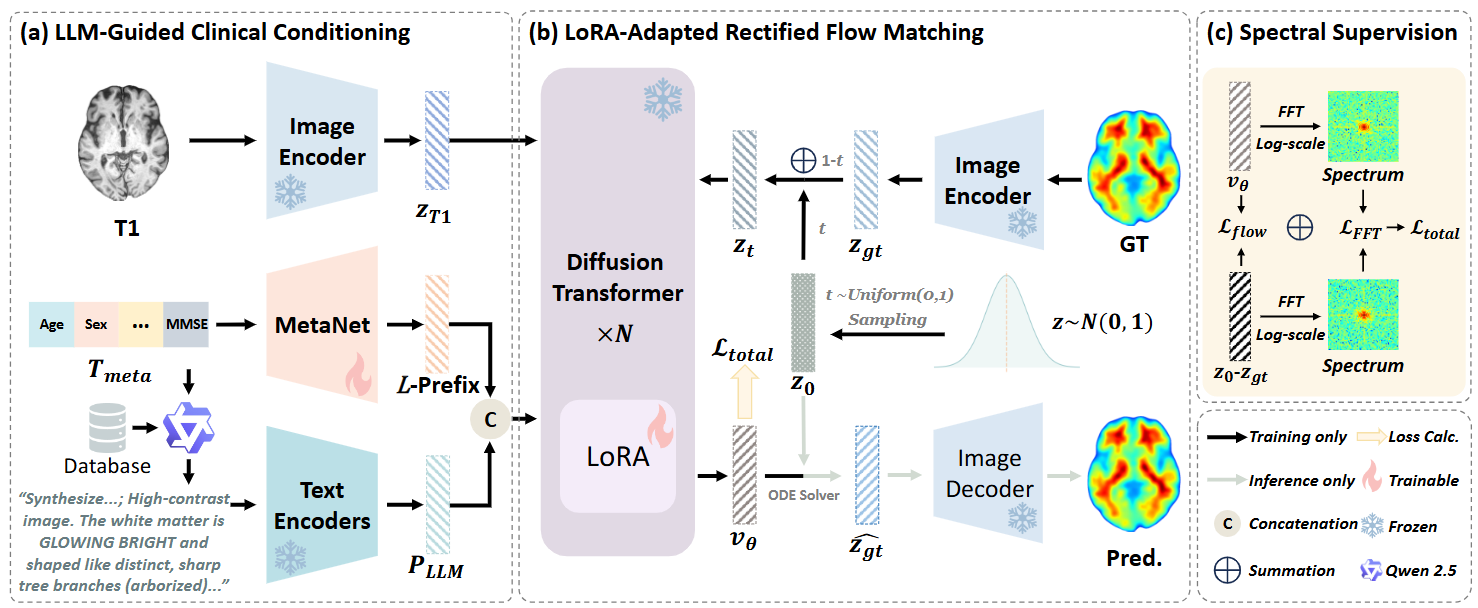 PETFlux: Taming Natural Foundation Models for Accurate MRI-to-PET SynthesisYuan Yin*, Honglin Xiong, Haolin Huang, Yonghao Li, Yan Kong, Yitao Zhu, Zhuoxin Jiang, Kaicong Sun, Dinggang Shen, and Qian Wang†In Medical Image Computing and Computer Assisted Intervention , 2026
PETFlux: Taming Natural Foundation Models for Accurate MRI-to-PET SynthesisYuan Yin*, Honglin Xiong, Haolin Huang, Yonghao Li, Yan Kong, Yitao Zhu, Zhuoxin Jiang, Kaicong Sun, Dinggang Shen, and Qian Wang†In Medical Image Computing and Computer Assisted Intervention , 2026Synthesizing PET from MRI offers a radiation-free route to functional biomarkers but remains fundamentally ill-posed due to the weak coupling between anatomy and metabolism. Existing medical generative models trained on limited molecular imaging data often overfit or generate artifacts, while natural-image foundation models cannot be directly transferred because their priors and semantics are misaligned with radiological domains. We introduce PETFlux, a task-aligned adaptation framework that repurposes a pretrained natural-image backbone for the specific demands of MRI-to-PET synthesis. The framework addresses the key barriers of domain mismatch, structural-functional ambiguity, and spatial over-smoothing through three synergistic strategies: (i) Low-Rank Adaptation (LoRA) via rectified flow matching to realign natural priors with PET distributions; (ii) LLM-augmented prefix tuning grounded in an evidence-based clinical knowledge base to inject patient-specific metabolic semantics; and (iii) a log-scale focal frequency loss to preserve clinically critical functional detail. Experiments on the ADNI dataset demonstrate that PETFlux achieves state-of-the-art synthesis fidelity and yields substantial gains in downstream diagnostic classification, highlighting a principled pathway for repurposing natural foundation models in molecular imaging by effectively integrating anatomical constraints and patient metadata. Code will be released upon acceptance.
- npj Digit. Med.
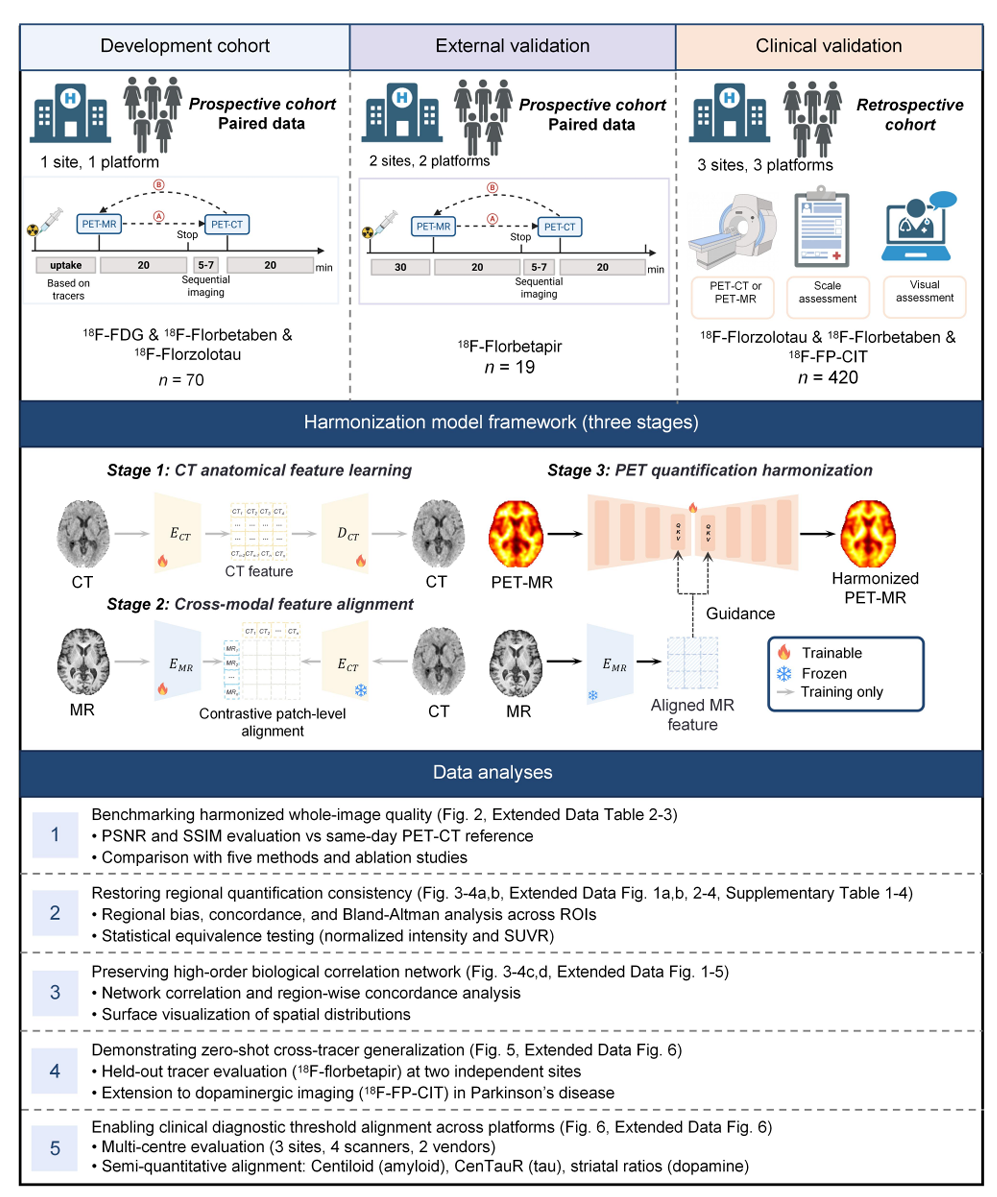 A unified deep learning framework for cross-platform harmonization of multi-tracer PET quantificationJing Wang*, Aocheng Zhong*, Qian Xu*, Haolin Huang*, Yuhua Zhu, Jiayin Lu, Min Wang, Jiehui Jiang, Chengyang Li, Ming Ni, Kaicong Sun, Yihui Guan, Jie Lu, Mei Tian, Dinggang Shen, Huiwei Zhang, Qian Wang†, and Chuan-Tao Zuo†npj Digital Medicine , 2026
A unified deep learning framework for cross-platform harmonization of multi-tracer PET quantificationJing Wang*, Aocheng Zhong*, Qian Xu*, Haolin Huang*, Yuhua Zhu, Jiayin Lu, Min Wang, Jiehui Jiang, Chengyang Li, Ming Ni, Kaicong Sun, Yihui Guan, Jie Lu, Mei Tian, Dinggang Shen, Huiwei Zhang, Qian Wang†, and Chuan-Tao Zuo†npj Digital Medicine , 2026Quantitative PET underpins diagnosis and treatment monitoring in neurodegenerative disease, yet systematic biases between PET-MRI and PET-CT preclude threshold transfer and cross-site comparability. We present a unified, anatomically guided deep-learning framework that harmonizes multi-tracer PET-MRI to PET-CT. The model learns CT-anchored attenuation representations with a Vision Transformer Autoencoder, aligns MRI features to CT space via contrastive objectives, and performs attention-guided residual correction. In paired same-day scans (N = 70; amyloid, tau, FDG), cross-platform bias fell by >80% while preserving inter-regional biological topology. The framework generalized zero-shot to held-out tracers (18F-florbetapir; 18F-FP-CIT) without retraining. Multicentre validation (N = 420; three sites, four vendors) reduced amyloid Centiloid discrepancies from 23.6 to 4.1 (within PET-CT test-retest precision) and aligned tau SUVR thresholds. These results enable platform-agnostic diagnostic cutoffs and reliable longitudinal monitoring when patients transition between modalities, establishing a practical route to scalable, radiation-sparing quantitative PET in therapeutic workflows.
2025
- Cell Rep. Med.
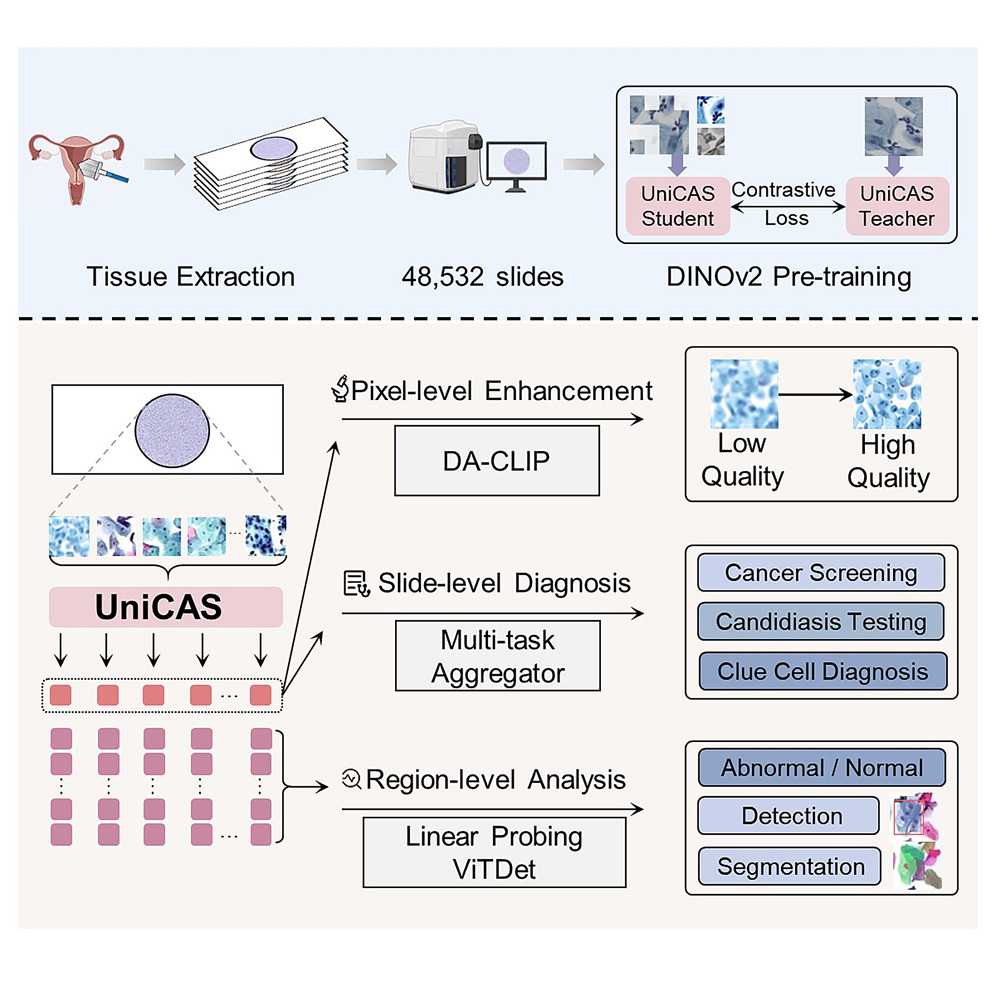 UniCAS: A Foundation Model for Cervical Cytology ScreeningHaotian Jiang*, Jiangdong Cai*, Zhenrong Shen, Mengjie Xu, Manman Fei, Haolin Huang, Xinyu Wang, Rui Bi, Dinggang Shen, Lichi Zhang†, and Qian Wang†Cell Reports Medicine , 2025
UniCAS: A Foundation Model for Cervical Cytology ScreeningHaotian Jiang*, Jiangdong Cai*, Zhenrong Shen, Mengjie Xu, Manman Fei, Haolin Huang, Xinyu Wang, Rui Bi, Dinggang Shen, Lichi Zhang†, and Qian Wang†Cell Reports Medicine , 2025Cervical abnormality screening is pivotal for prevention and treatment. However, the substantial size of whole slide images (WSIs) makes examination labor-intensive and time-consuming. Current deep learning-based approaches struggle with the morphological diversity of cervical cytology and require specialized models for distinct diagnostic tasks, leading to fragmented workflows. Here, we present UniCAS, a cytology foundation model pre-trained on 48,532 cervical WSIs encompassing diverse patient demographics and pathological conditions. UniCAS enables various clinical analysis tasks, achieving state-of-the-art performance in slide-level diagnosis, region-level analysis, and pixel-level image enhancement. In particular, by integrating a multi-task aggregator for slide-level diagnosis, UniCAS achieves area under the curve (AUC) values of 92.60%, 92.58%, and 98.39% for cancer screening, candidiasis testing, and clue cell diagnosis, respectively, while reducing diagnostic time by 70% compared with conventional approaches. This work establishes a paradigm for efficient multi-scale analysis in automated cervical cytology, bridging the gap between computational pathology and clinical diagnostic workflows.
- Med. Image Anal.
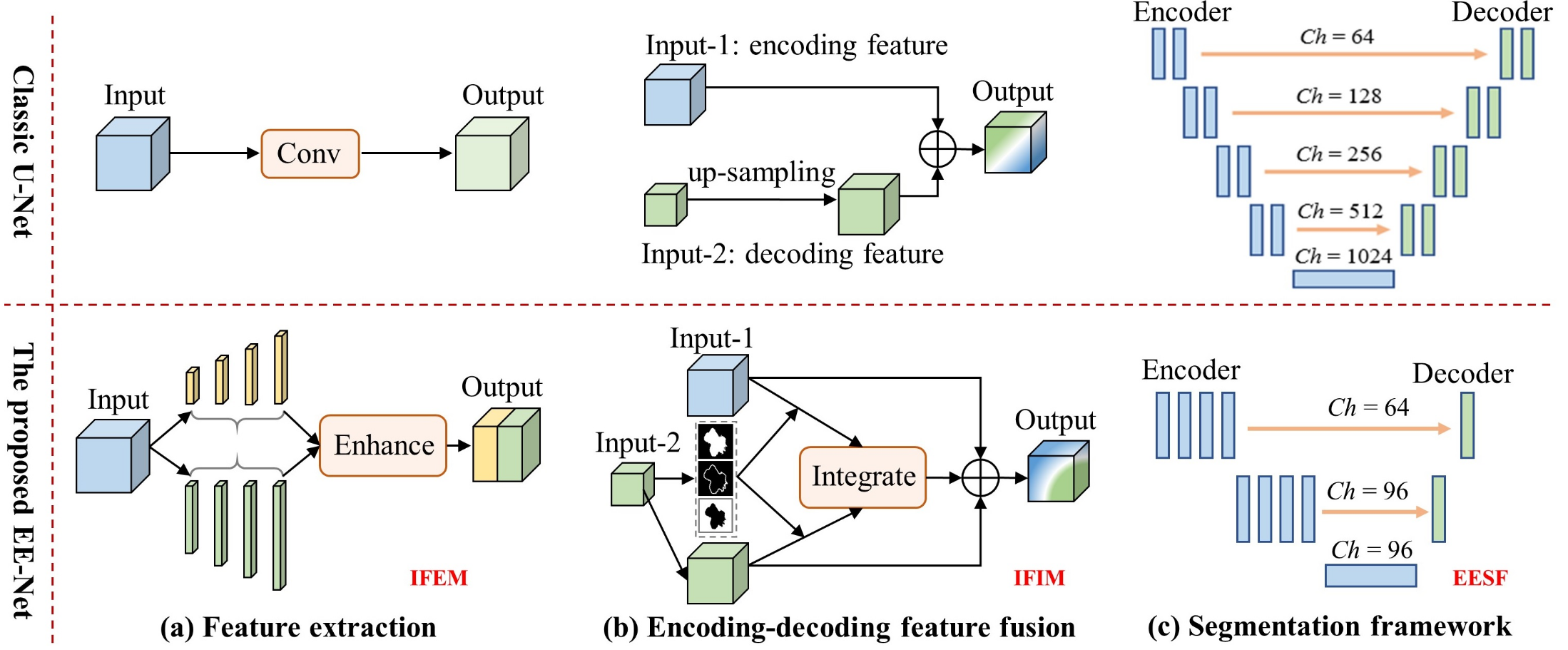 Improving the performance of medical image segmentation with instructive feature learningDuwei Dai, Caixia Dong, Haolin Huang, Fan Liu, Zongfang Li, and Songhua Xu†Medical Image Analysis , 2025
Improving the performance of medical image segmentation with instructive feature learningDuwei Dai, Caixia Dong, Haolin Huang, Fan Liu, Zongfang Li, and Songhua Xu†Medical Image Analysis , 2025Although deep learning models have greatly automated medical image segmentation, they still struggle with complex samples, especially those with irregular shapes, notable scale variations, or blurred boundaries. One key reason for this is that existing methods often overlook the importance of identifying and enhancing the instructive features tailored to various targets, thereby impeding optimal feature extraction and transmission. To address these issues, we propose two innovative modules: an Instructive Feature Enhancement Module (IFEM) and an Instructive Feature Integration Module (IFIM). IFEM synergistically captures rich detailed information and local contextual cues within a unified convolutional module through flexible resolution scaling and extensive information interplay, thereby enhancing the network’s feature extraction capabilities. Meanwhile, IFIM explicitly guides the fusion of encoding-decoding features to create more discriminative representations through sensitive intermediate predictions and omnipresent attention operations, thus refining contextual feature transmission. These two modules can be seamlessly integrated into existing segmentation frameworks, significantly boosting their performance. Furthermore, to achieve superior performance with substantially reduced computational demands, we develop an effective and efficient segmentation framework (EESF). Unlike traditional U-Nets, EESF adopts a shallower and wider asymmetric architecture, achieving a better balance between fine-grained information retention and high-order semantic abstraction with minimal learning parameters. Ultimately, by incorporating IFEM and IFIM into EESF, we construct EE-Net, a high-performance and low-resource segmentation network. Extensive experiments across six diverse segmentation tasks consistently demonstrate that EE-Net outperforms a wide range of competing methods in terms of segmentation performance, computational efficiency, and learning ability.
- MICCAI (Early Accept)
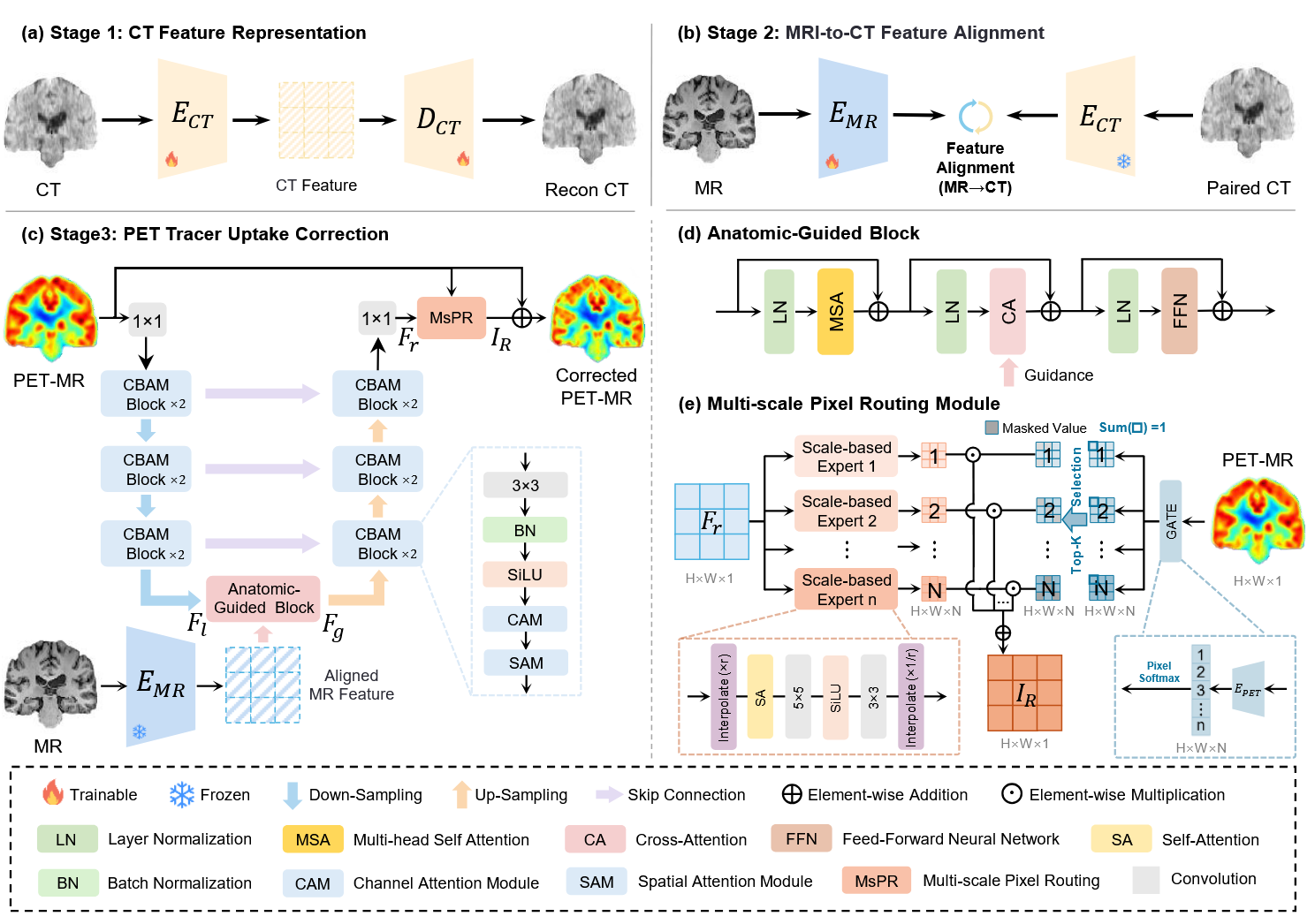 Multi-Tracer Uptake Correction for PET-MR via Aligned-Feature Guidance and Multi-scale Pixel-adaptive RoutingAocheng Zhong*, Haolin Huang*, Jing Wang*, Zhenrong Shen, Haiyu Song, Yuhua Zhu, Yang Liu, Junlei Wu, Chuantao Zuo†, and Qian Wang†In Medical Image Computing and Computer Assisted Intervention , 2025
Multi-Tracer Uptake Correction for PET-MR via Aligned-Feature Guidance and Multi-scale Pixel-adaptive RoutingAocheng Zhong*, Haolin Huang*, Jing Wang*, Zhenrong Shen, Haiyu Song, Yuhua Zhu, Yang Liu, Junlei Wu, Chuantao Zuo†, and Qian Wang†In Medical Image Computing and Computer Assisted Intervention , 2025Positron Emission Tomography combined with Magnetic Resonance (PET-MR) imaging has emerged as a promising modality that offers both soft tissue and biochemical function information, while substantially reducing radiation exposure compared to PET-CT imaging. However, systematic clinical evaluations reveal notable discrepancies in standardized uptake value ratios between PET-MR and PET-CT scans, largely due to the inherent limitations of MR-based PET attenuation correction. To address this issue, we propose a unified uptake correction framework to harmonize PET-MR images with PET-CT scans across different tracers. This framework employs a three-stage training scheme. The first stage learns to represent CT features, aiming to capture condensed anatomical patterns associated with PET imaging. The second stage aligns MR features to the fixed CT features learned in the first stage, thereby enabling the transfer of anatomical prior knowledge from CT to MR features. The third stage integrates aligned MR features to guide PET-MR tracer uptake correction and uses a Multi-scale Pixel Routing module to mitigate interference among different tracers. We conduct comprehensive experiments on 70 patients with three distinct tracers to demonstrate the superiority of our framework over existing methods in PET-MR harmonization with PET-CT images. This work represents the first investigation and solution for multi-tracer quantification discrepancies between PET-MR and standard PET-CT, potentially advancing the clinical standardization of PET-MR imaging.
- MICCAI (Early Accept)
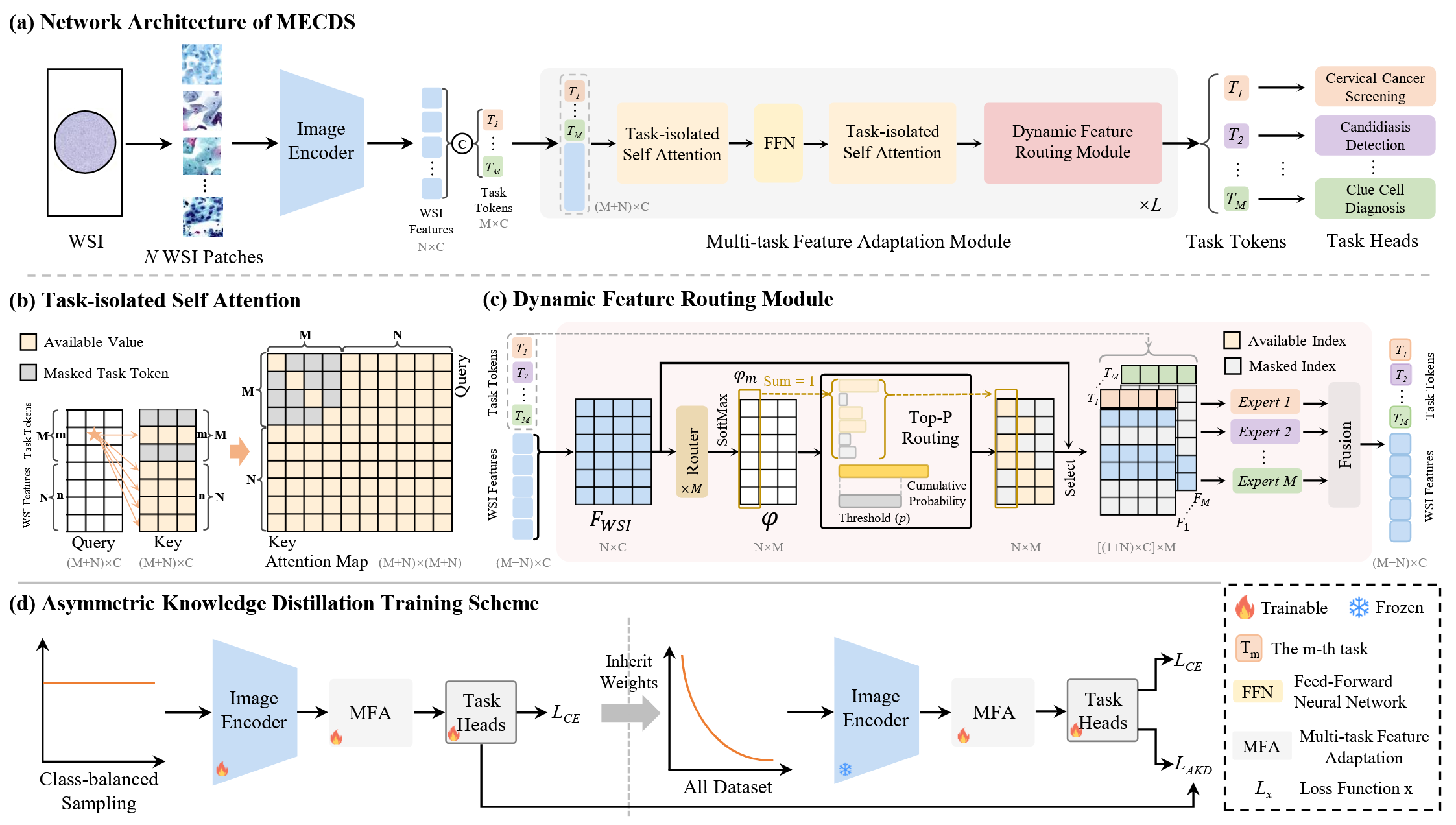 Multi-task Screening for Cervical Diseases via Feature Routing and Asymmetric DistillationHaotian Jiang*, Haolin Huang*, Jiangdong Cai, Mengjie Xu, Zhenrong Shen, Manman Fei, Xinyu Wang, Lichi Zhang†, and Qian Wang†In Medical Image Computing and Computer Assisted Intervention , 2025
Multi-task Screening for Cervical Diseases via Feature Routing and Asymmetric DistillationHaotian Jiang*, Haolin Huang*, Jiangdong Cai, Mengjie Xu, Zhenrong Shen, Manman Fei, Xinyu Wang, Lichi Zhang†, and Qian Wang†In Medical Image Computing and Computer Assisted Intervention , 2025Cervical diseases present a significant global health challenge, especially in resource-limited regions with scarce specialized healthcare. Traditional analysis methods for thin-prep cytologic tests and whole slide images are hindered by their reliance on time-consuming processes and expert knowledge. Although AI-driven approaches have advanced single-task screening, they often face difficulties adapting to multi-task workflows and handling extreme class imbalance, thereby limiting their practical deployment in real clinical settings. To address these challenges, we propose a novel framework, MECDS, for multi-task early screening of cervical diseases. Specifically, we design dynamic feature routing to prevent inter-task interference and selectively process task-relevant features. Furthermore, we employ asymmetric attention levels during knowledge distillation to address class imbalance, thus enhancing performance across diverse classes. Our extensive experiments on a large-scale dataset comprising 29,774 whole slide images demonstrate that MECDS surpasses existing single-task and multi-task models across three key screening tasks: cervical cancer, candidiasis, and clue cell detection. Additionally, MECDS exhibits remarkable extensibility, allowing for the efficient integration of novel diagnostic tasks without the need for exhaustive retraining. This unified framework holds great promise for improving comprehensive screening programs in resource-constrained healthcare environments, potentially advancing early detection and improving health outcomes.
- MICCAI Workshop (Oral)
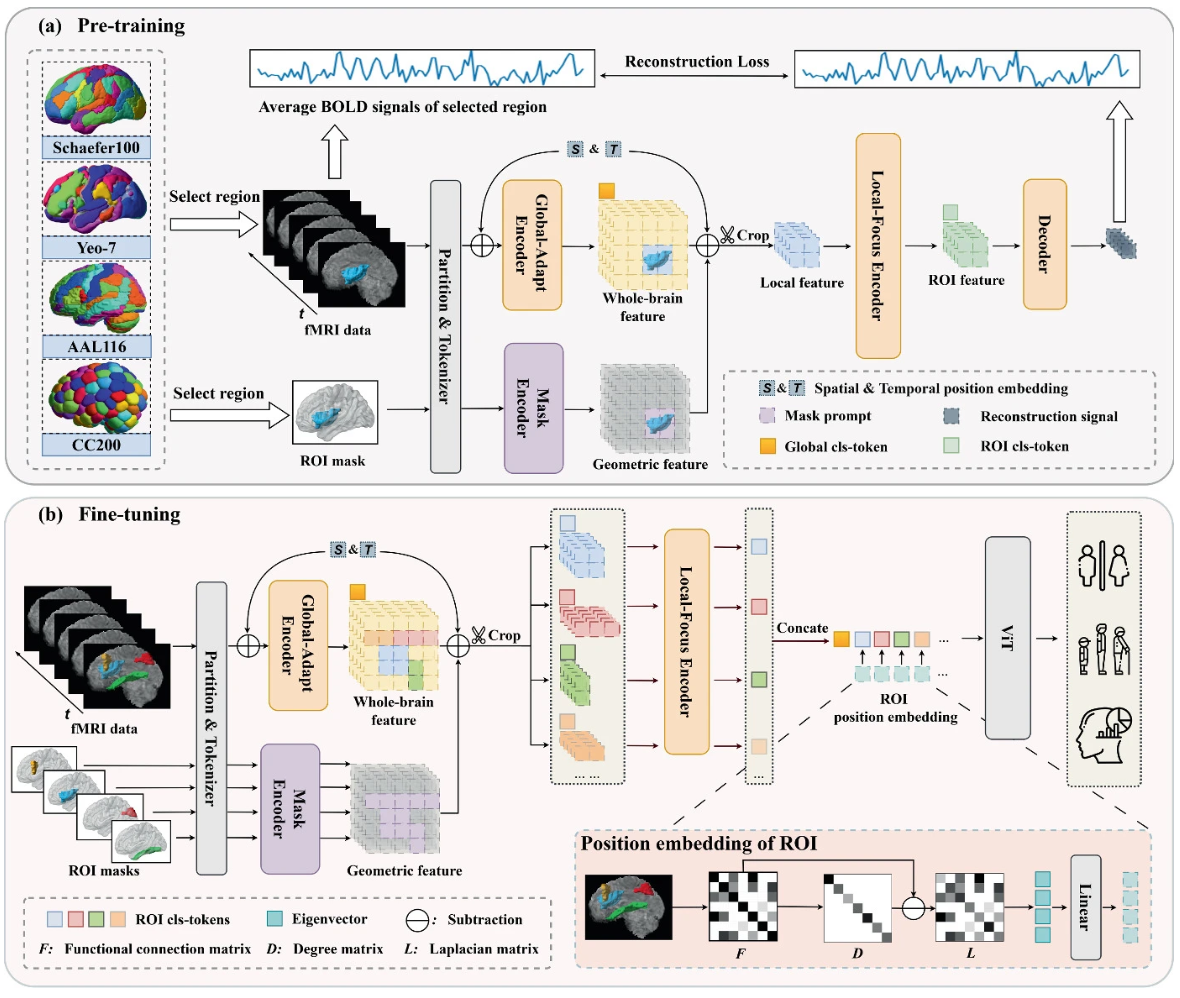 Region-adapted Representation Learning for Resting-state fMRIXinyu Wang, Mengjun Liu, Haolin Huang, Haotian Jiang, Mengjie Xu, and Qian Wang†In MICCAI 2025 Workshop on Predictive Intelligence in Medicine (PRIME) , 2025
Region-adapted Representation Learning for Resting-state fMRIXinyu Wang, Mengjun Liu, Haolin Huang, Haotian Jiang, Mengjie Xu, and Qian Wang†In MICCAI 2025 Workshop on Predictive Intelligence in Medicine (PRIME) , 2025Resting-state functional magnetic resonance imaging (rs-fMRI) serves as a powerful tool for studying brain function, yet deriving the optimal representation of brain function remains a challenge. Traditional methods often rely on region of interest (ROI)-based analyses, which simplify complexity and reduce noise but are constrained by fixed ROI partitions and averaged voxel signals, potentially missing valuable information. In our study, we introduce a novel framework for autonomously learning representations for any brain region directly from voxel-level fMRI data. This approach is designed to manage arbitrary ROIs. It incorporates two primary stages: During the pre-training stage, a global-adapt encoder captures whole-brain feature representations from 4D fMRI data, while a mask encoder processes brain region masks to extract geometric features. These features merge with their corresponding fMRI representations to reconstruct the mean BOLD signal of the region, facilitating self-supervised training. By providing a range of brain region masks, our framework enables the learning of representations for a set of arbitrary ROIs, whether derived from established brain atlases or crafted manually. In the fine-tuning stage, the pre-trained model adapts to downstream tasks like gender classification, age prediction, and intelligence prediction. Experiments conducted with the HCP and UK Biobank datasets reveal that our method surpasses competing approaches, delivering highly interpretable and neurofunctionally relevant brain region representations.
- ICASSP
 DCIM-AVSR: Efficient Audio-Visual Speech Recognition via Dual Conformer Interaction ModuleXinyu Wang, Haotian Jiang, Haolin Huang, Yu Fang, Mengjie Xu, and Qian Wang†In IEEE International Conference on Acoustics, Speech and Signal Processing , 2025
DCIM-AVSR: Efficient Audio-Visual Speech Recognition via Dual Conformer Interaction ModuleXinyu Wang, Haotian Jiang, Haolin Huang, Yu Fang, Mengjie Xu, and Qian Wang†In IEEE International Conference on Acoustics, Speech and Signal Processing , 2025Speech recognition is the technology that enables machines to interpret and process human speech, converting spoken language into text or commands. This technology is essential for applications such as virtual assistants, transcription services, and communication tools. The Audio-Visual Speech Recognition (AVSR) model enhances traditional speech recognition, particularly in noisy environments, by incorporating visual modalities like lip movements and facial expressions. While traditional AVSR models trained on large-scale datasets with numerous parameters can achieve remarkable accuracy, often surpassing human performance, they also come with high training costs and deployment challenges. To address these issues, we introduce an efficient AVSR model that reduces the number of parameters through the integration of a Dual Conformer Interaction Module (DCIM). In addition, we propose a pre-training method that optimizes model performance by fine-tuning. Unlike conventional models that require the system to independently learn the hierarchical relationship between audio and visual modalities, our approach incorporates this distinction directly into the model architecture. This design enhances both efficiency and performance, resulting in a more practical and effective solution for AVSR tasks.
- CVPR (Highlight)
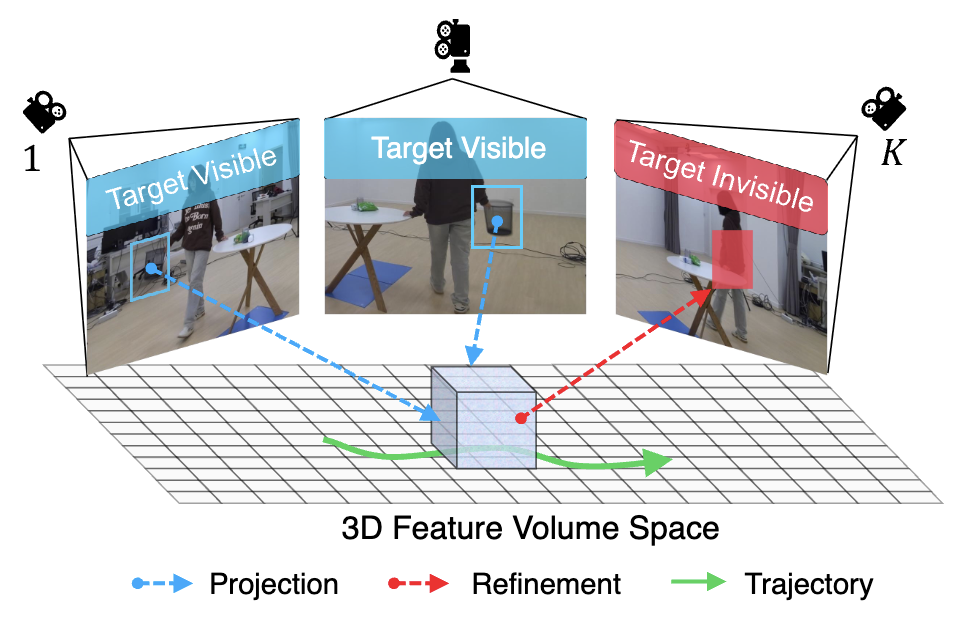 MITracker: Multi-View Integration for Visual Object TrackingMengjie Xu*, Yitao Zhu*, Haotian Jiang, Jiaming Li, Zhenrong Shen, Sheng Wang, Haolin Huang, Xinyu Wang, Qing Yang, Han Zhang, and Qian Wang†In IEEE/CVF Computer Vision and Pattern Recognition Conference , 2025
MITracker: Multi-View Integration for Visual Object TrackingMengjie Xu*, Yitao Zhu*, Haotian Jiang, Jiaming Li, Zhenrong Shen, Sheng Wang, Haolin Huang, Xinyu Wang, Qing Yang, Han Zhang, and Qian Wang†In IEEE/CVF Computer Vision and Pattern Recognition Conference , 2025Multi-view object tracking (MVOT) offers promising solutions to challenges such as occlusion and target loss, which are common in traditional single-view tracking. However, progress has been limited by the lack of comprehensive multi-view datasets and effective cross-view integration methods. To overcome these limitations, we compiled a Multi-View object Tracking (MVTrack) dataset of 234K high-quality annotated frames featuring 27 distinct objects across various scenes. In conjunction with this dataset, we introduce a novel MVOT method, Multi-View Integration Tracker (MITracker), to efficiently integrate multi-view object features and provide stable tracking outcomes. MITracker can track any object in video frames of arbitrary length from arbitrary viewpoints. The key advancements of our method over traditional single-view approaches come from two aspects: (1) MITracker transforms 2D image features into a 3D feature volume and compresses it into a bird’s eye view (BEV) plane, facilitating inter-view information fusion; (2) we propose an attention mechanism that leverages geometric information from fused 3D feature volume to refine the tracking results at each view. MITracker outperforms existing methods on the MVTrack and GMTD datasets, achieving state-of-the-art performance.
- EJNMMI
 Cross-Modality PET Image Synthesis for Parkinson’s Disease Diagnosis: A Leap from [18F]FDG to [11C]CFTZhenrong Shen*, Jing Wang*, Haolin Huang, Jiaying Lu, Jingjie Ge, Honglin Xiong, Ping Wu, Zizhao Ju, Huamei Lin, Yuhua Zhu, Yunhao Yang, Fengtao Liu, Yihui Guan, Kaicong Sun, Jian Wang, Qian Wang†, and Chuantao Zuo†European Journal of Nuclear Medicine and Molecular Imaging , Jan 2025
Cross-Modality PET Image Synthesis for Parkinson’s Disease Diagnosis: A Leap from [18F]FDG to [11C]CFTZhenrong Shen*, Jing Wang*, Haolin Huang, Jiaying Lu, Jingjie Ge, Honglin Xiong, Ping Wu, Zizhao Ju, Huamei Lin, Yuhua Zhu, Yunhao Yang, Fengtao Liu, Yihui Guan, Kaicong Sun, Jian Wang, Qian Wang†, and Chuantao Zuo†European Journal of Nuclear Medicine and Molecular Imaging , Jan 2025Purpose: Dopamine transporter [11C]CFT PET is highly effective for diagnosing Parkinson’s Disease (PD), whereas it is not widely available in most hospitals. To develop a deep learning framework to synthesize [11C]CFT PET images from real [18F]FDG PET images and leverage their cross-modal correlation to distinguish PD from normal control (NC). Methods: We developed a deep learning framework to synthesize [11C]CFT PET images from real [18F]FDG PET images, and leveraged their cross-modal correlation to distinguish PD from NC. A total of 604 participants (274 with PD and 330 with NC) who underwent [11C]CFT and [18F]FDG PET scans were included. The quality of the synthetic [11C]CFT PET images was evaluated through quantitative comparison with the ground-truth images and radiologist visual assessment. The evaluations of PD diagnosis performance were conducted using biomarker-based quantitative analyses (using striatal binding ratios from synthetic [11C]CFT PET images) and the proposed PD classifier (incorporating both real [18F]FDG and synthetic [11C]CFT PET images). Results: Visualization result shows that the synthetic [11C]CFT PET images resemble the real ones with no significant differences visible in the error maps. Quantitative evaluation demonstrated that synthetic [11C]CFT PET images exhibited a high peak signal-to-noise ratio (PSNR: 25.0–28.0) and structural similarity (SSIM: 0.87–0.96) across different unilateral striatal subregions. The radiologists achieved a diagnostic accuracy of 91.9% (± 2.02%) based on synthetic [11C]CFT PET images, while biomarker-based quantitative analysis of the posterior putamen yielded an AUC of 0.912 (95% CI, 0.889–0.936), and the proposed PD Classifier achieved an AUC of 0.937 (95% CI, 0.916–0.957). Conclusion: By bridging the gap between [18F]FDG and [11C]CFT, our deep learning framework can significantly enhance PD diagnosis without the need for [11C]CFT tracers, thereby expanding the reach of advanced diagnostic tools to clinical settings where [11C]CFT PET imaging is inaccessible.
- JMRI
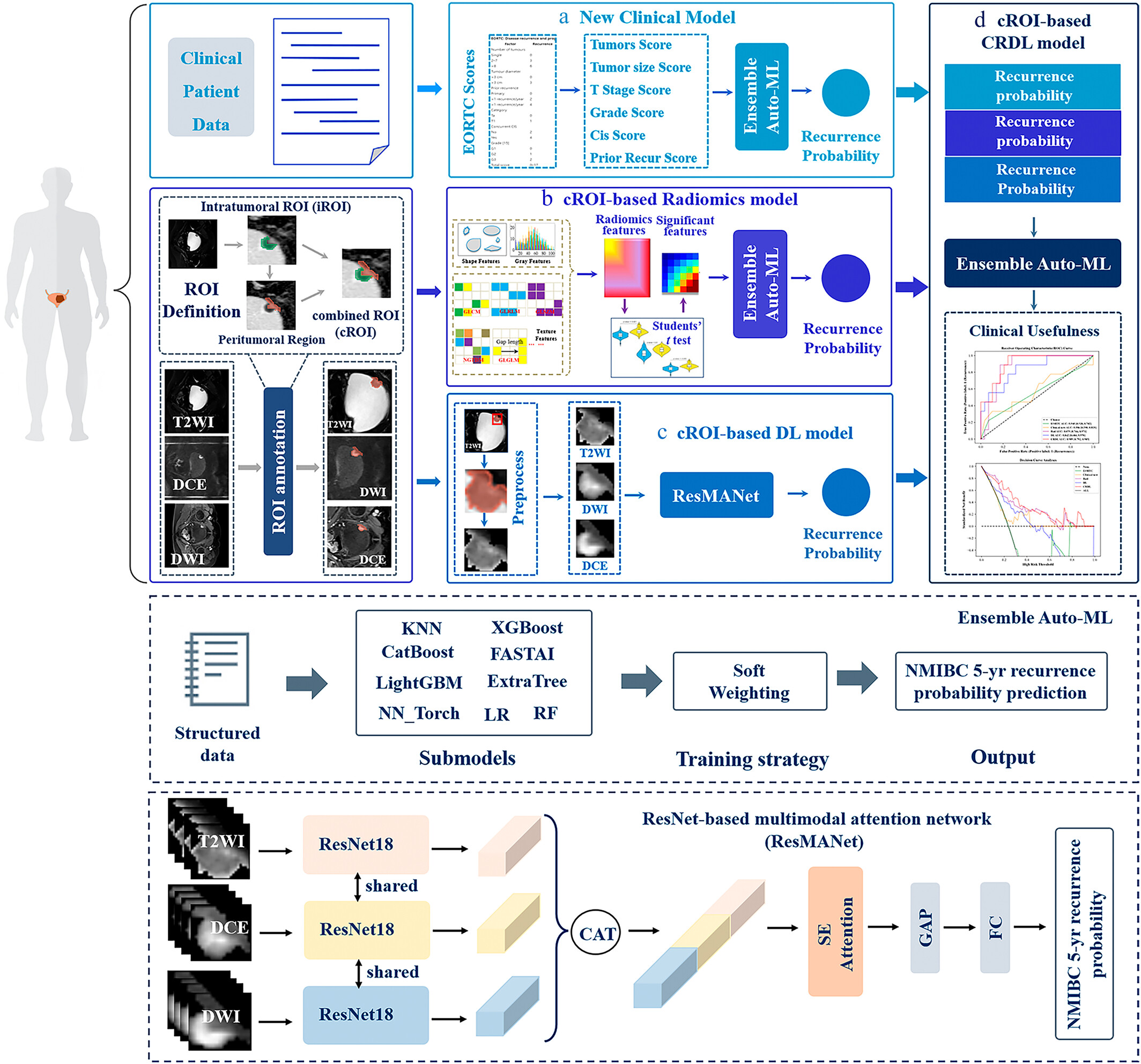 Multiparametric MRI-Based Deep Learning Radiomics Model for Assessing 5-Year Recurrence Risk in Non-Muscle Invasive Bladder CancerHaolin Huang*, Yiping Huang*, Joshua D. Kaggie, Qian Cai, Peng Yang, Jie Wei, Lijuan Wang, Yan Guo, Hongbing Lu, Huanjun Wang†, and Xiaopan Xu†Journal of Magnetic Resonance Imaging , Mar 2025
Multiparametric MRI-Based Deep Learning Radiomics Model for Assessing 5-Year Recurrence Risk in Non-Muscle Invasive Bladder CancerHaolin Huang*, Yiping Huang*, Joshua D. Kaggie, Qian Cai, Peng Yang, Jie Wei, Lijuan Wang, Yan Guo, Hongbing Lu, Huanjun Wang†, and Xiaopan Xu†Journal of Magnetic Resonance Imaging , Mar 2025Background: Accurately assessing 5-year recurrence rates is crucial for managing non-muscle-invasive bladder carcinoma (NMIBC). However, the European Organization for Research and Treatment of Cancer (EORTC) model exhibits poor performance. Purpose: To investigate whether integrating multiparametric MRI (mp-MRI) with clinical factors improves NMIBC 5-year recurrence risk assessment. Study Type: Retrospective. Population: One hundred ninety-one patients (median age, 65 years; age range, 54–73 years; 27 females) underwent mp-MRI between 2011 and 2017, and received ≥5-year follow-ups. They were divided into a training cohort (N = 115) and validation/testing cohorts (N = 38 in each). Recurrence rates were 23.5% (27/115) in the training cohort and 23.7% (9/38) in both validation and testing cohorts. Field Strength/Sequence: 3-T, fast spin echo T2-weighted imaging (T2WI), single-shot echo planar diffusion-weighted imaging (DWI), and volumetric spoiled gradient echo dynamic contrast-enhanced (DCE) sequences. Assessment: Radiomics and deep learning (DL) features were extracted from the combined region of interest (cROI) including intratumoral and peritumoral areas on mp-MRI. Four models were developed, including clinical, cROI-based radiomics, DL, and clinical-radiomics-DL (CRDL) models. Statistical Tests: Student’s t-tests, DeLong’s tests with Bonferroni correction, receiver operating characteristics with the area under the curves (AUCs), Cox proportional hazard analyses, Kaplan–Meier plots, SHapley Additive exPlanations (SHAP) values, and Akaike information criterion for clinical usefulness. A P-value <0.05 was considered statistically significant. Results: The cROI-based CRDL model showed superior performance (AUC 0.909; 95% CI: 0.792–0.985) compared to other models in the testing cohort for assessing 5-year recurrence in NMIBC. It achieved the highest Harrell’s concordance index (0.804; 95% CI: 0.749–0.859) for estimating recurrence-free survival. SHAP analysis further highlighted the substantial role (22%) of the radiomics features in NMIBC recurrence assessment. Data Conclusion: Integrating cROI-based radiomics and DL features from preoperative mp-MRI with clinical factors could improve 5-year recurrence risk assessment in NMIBC. Evidence Level: 3 Technical Efficacy: Stage 3
2024
- MICCAI (Young Scientist Award)
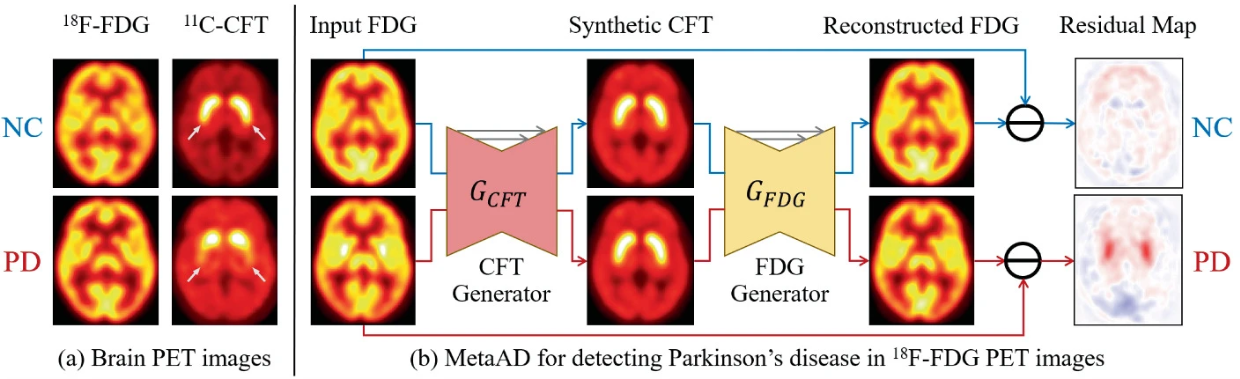 MetaAD: Metabolism-Aware Anomaly Detection for Parkinson’s Disease in 3D 18F-FDG PETHaolin Huang*, Zhenrong Shen*, Jing Wang*, Xinyu Wang, Jiaying Lu, Huamei Lin, Jingjie Ge, Chuantao Zuo†, and Qian Wang†In Medical Image Computing and Computer Assisted Intervention , Oct 2024
MetaAD: Metabolism-Aware Anomaly Detection for Parkinson’s Disease in 3D 18F-FDG PETHaolin Huang*, Zhenrong Shen*, Jing Wang*, Xinyu Wang, Jiaying Lu, Huamei Lin, Jingjie Ge, Chuantao Zuo†, and Qian Wang†In Medical Image Computing and Computer Assisted Intervention , Oct 2024This paper was early accepted, invited for oral presentation, selected as a best paper candidate, and received the Young Scientist Award
The dopamine transporter (DAT) imaging such as 11C-CFT PET has shown significant superiority in diagnosing Parkinson’s Disease (PD). However, most hospitals have no access to DAT imaging but instead turn to the commonly used 18F-FDG PET, which may not show major abnormalities of PD at visual analysis and thus hinder the performance of computer-aided diagnosis (CAD). To tackle this challenge, we propose a Metabolism-aware Anomaly Detection (MetaAD) framework to highlight abnormal metabolism cues of PD in 18F-FDG PET scans. MetaAD converts the input FDG image into a synthetic CFT image with healthy patterns, and then reconstructs the FDG image by a reversed modality mapping. The visual differences between the input and reconstructed images serve as indicators of PD metabolic anomalies. A dual-path training scheme is adopted to prompt the generators to learn an explicit normal data distribution via cyclic modality translation while enhancing their abilities to memorize healthy metabolic characteristics. The experiments reveal that MetaAD not only achieves superior performance in visual interpretability and anomaly detection for PD diagnosis, but also shows effectiveness in assisting supervised CAD methods. Our code is available at https://github.com/MedAIerHHL/MetaAD.
2022
- JCRCO
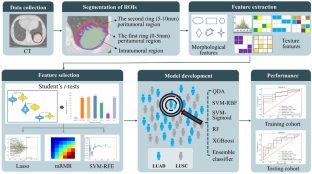 Intratumoral and Peritumoral CT-Based Radiomics Strategy Reveals Distinct Subtypes of Non-Small-Cell Lung CancerXing Tang*, Haolin Huang*, Peng Du, Lijuan Wang, Hong Yin, and Xiaopan Xu†Journal of Cancer Research and Clinical Oncology , Oct 2022
Intratumoral and Peritumoral CT-Based Radiomics Strategy Reveals Distinct Subtypes of Non-Small-Cell Lung CancerXing Tang*, Haolin Huang*, Peng Du, Lijuan Wang, Hong Yin, and Xiaopan Xu†Journal of Cancer Research and Clinical Oncology , Oct 2022Purpose: To evaluate a new radiomics strategy that incorporates intratumoral and peritumoral features extracted from lung CT images with ensemble learning for pretreatment prediction of lung squamous cell carcinoma (LUSC) and lung adenocarcinoma (LUAD). Methods: A total of 105 patients (47 LUSC and 58 LUAD) with pretherapy CT scans were involved in this retrospective study, and were divided into training (n = 73) and testing (n = 32) cohorts. Seven categories of radiomics features involving 3078 metrics in total were extracted from the intra- and peritumoral regions of each patient’s CT data. Student’s t tests in combination with three feature selection methods were adopted for optimal features selection. An ensemble classifier was developed using five common machine learning classifiers with these optimal features. The performance was assessed using both training and testing cohorts, and further compared with that of Visual Geometry Group-16 (VGG-16) deep network for this predictive task. Results: The classification models developed using optimal feature subsets determined from intratumoral region and peritumoral region with the ensemble classifier achieved mean area under the curve (AUC) of 0.87, 0.83 in the training cohort and 0.66, 0.60 in the testing cohort, respectively. The model developed by using the optimal feature subset selected from both intra- and peritumoral regions with the ensemble classifier achieved great performance improvement, with AUC of 0.87 and 0.78 in both cohorts, respectively, which are also superior to that of VGG-16 (AUC of 0.68 in the testing cohort). Conclusions: The proposed new radiomics strategy that extracts image features from the intra- and peritumoral regions with ensemble learning could greatly improve the diagnostic performance for the histological subtype stratification in patients with NSCLC.